Chatbot Training Guide
Train Chatbots With Clean Data
The data you provide is utilized as the CONTEXT INFORMATION for the chatbot to respond to queries. The cleaner the CONTEXT INFORMATION, the higher the likelihood that the chatbot will discern the essential messages within the context to accurately address the query. This is especially critical when using GPT-4o mini as the underlying model.
Sources of Polluted Data
Polluted data can occur during the extraction of text content from PDF files or through website crawling for various purposes:
Unrecognized Unicode
Some PDF texts use specialized Unicode encoding as a copy-protection measure. Consequently, extracting text from these PDF files may result in "garbled code," which appears unreadable and incomprehensible. This garbled code, when used as context information for a chatbot, may hinder its performance. To ensure the integrity of the extracted text, it is advisable to preview the content by clicking the eye icon to check for any instances of garbled code. Below is an example of garbled code from a PDF file.
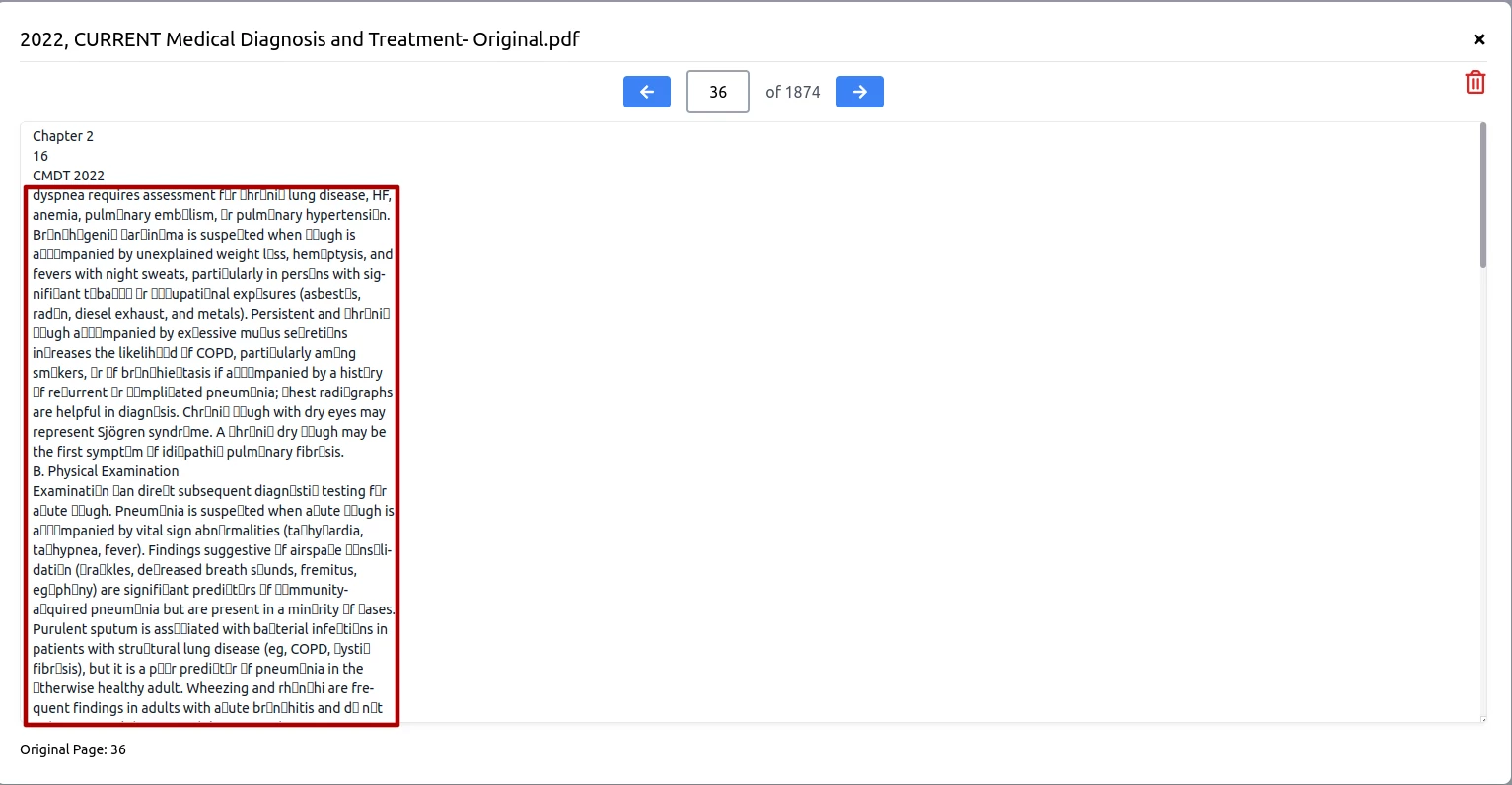
The solution to fix the 'garbled code' issue is to use OCR packages to convert the PDF file to another PDF file with the normal encoding. For example you can use the following command in ubuntu
ocrmypdf --force-ocr input.pdf output.pdf
After converting the PDF file with normal encoding, you can upload the file again. The unreadable text will be readable.
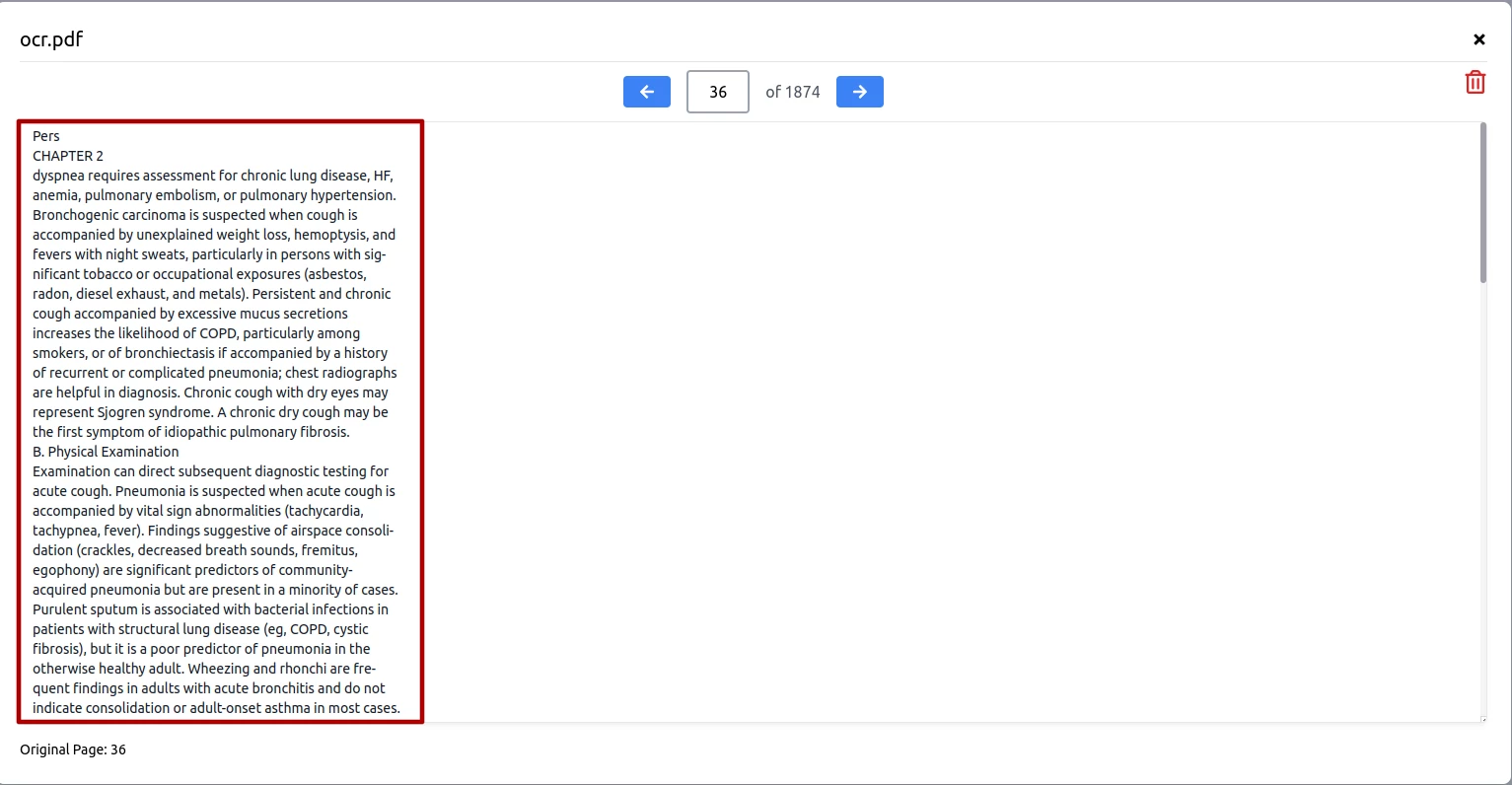
Redundant Metadata
Both PDF files and websites often contain extensive metadata that does not provide valuable information but occupies significant text space. This metadata is superfluous and consumes space that could be better used for relevant content. Removing this metadata can help streamline the data, although it typically requires considerable manual effort. This is a key reason why we recommend that Shopify/Woocommerce store owners import product details directly rather than scraping websites, as metadata can clutter the data with irrelevant information.
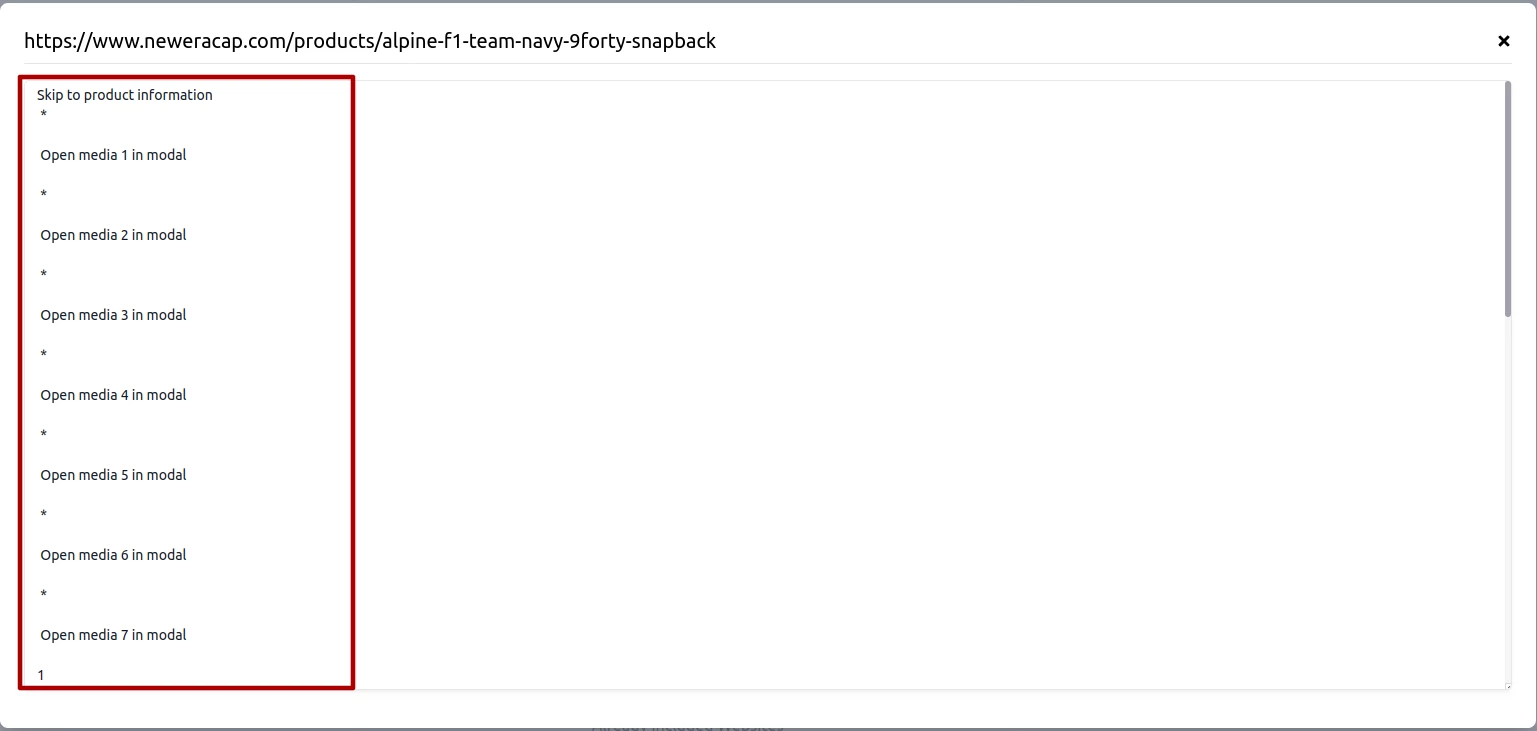
To address this issue, it is advisable to manually condense the useful information and then upload the consolidated content into the database.
Frequently Asked Questions
Why does clean training data matter so much for chatbot quality?
Your uploaded content becomes the context information used to answer questions, so cleaner context makes it easier for the chatbot to identify the right information and respond accurately, especially when using GPT-4o mini.
What are the main sources of polluted training data described in the guide?
Two main problems: unrecognized Unicode that creates garbled PDF text, and redundant metadata from PDFs or websites that takes up space without adding useful information.
How can I fix garbled text extracted from PDF files?
The guide recommends previewing extracted text with the eye icon and, if the PDF contains garbled code, running OCR on it first. The example command shown is ocrmypdf --force-ocr input.pdf output.pdf.
Why does the guide recommend importing store products directly instead of scraping websites?
Because direct product imports avoid the redundant metadata that often comes with scraped websites, which can clutter the training data with low-value content.